이 글은 Netty 이야기: 커널 관점에서 본 I/O 모델 을 바탕으로 제기 이해하고 부족한 점을 찾아 정리한 글입니다.
아마존 프리 티어에서 작은 개인 프로젝트를 테스트 하면서, 내 프로젝트가 생각보다 많은 트래픽을 감당하지 못하는걸 깨닫게 됐다.
그러면서 '대용량 트래픽을 효과적으로 제어하려면 어떻게 해야 할까?' 라는 의문이 자연스럽게 생겼고, Tomcat과 Gc를 튜닝하며 관련 내용을 찾아보던 중 Netty라는 클라이언트-서버 프레임워크를 접하게 되었다.
Netty는 비교적 간단한 코드와 구성만으로도 고성능의 비동기 네트워크 서버를 구축할 수 있었고,
이 프레임워크를 깊이 공부하면 대용량 트래픽을 처리하는 데 중요한 인사이트를 얻을 수 있을 것 같았다.
그래서 Netty 관련 자료를 찾아보던 중, 공식 홈페이지에서 I/O 모델부터 코드 분석까지 정리된 좋은 글을 발견했다.
이를 공부하면서 다시 정리하고 싶어 이 글을 작성하게 되었다.

네트워크 데이터는 계층을 통해 전달되는데, linux의 내부에서 어떻게 앱까지 데이터를 전달하는가를 설명하는게 이 글의 목표이다.
H/W
네트워크 데이터가 네트워크 전송을 통해 네트워크 카드(NIC)에 도달하면 DMA(Direct Memory Access)를 통해 링 버퍼 (RingBuffer)에 놓인다.
Direct Memory Access란?
특정 하드웨어 하위 시스템이 중앙 처리 장치 (CPU) 와 독립적으로 주 시스템 메모리에 액세스할 수 있도록 하는 컴퓨터 시스템의 기능이다.
DMA가 없는경우, CPU가 I/O장치와 직접 데이터를 주고 받아야하므로, 그 동안 다른 작업을 할 수 없게된다.
DMA를 사용함으로써 CPU는 DMAC(DAM Controller)에게 메모리와, I/O 장치 데이터 전송을 맡기고, DMAC가 전송을 수행하는 동안 CPU가 다른 작업을 수행할 수 있다.
전송이 끝나면 DMAC가 인터럽트를 발생시켜 CPU에게 완료를 알린다.
RingBuffer
RingBuffer는 NIC가 시작될 때 할당되고 초기화되는 링 버퍼 큐로, RingBuffer가 가득 차면 새로 온 패킷은 버려진다.
KERNEL
네트워크 카드(NIC)는 DMA(Direct Memory Access) 작업이 완료되면 '하드 인터럽트'(하드웨어 인터럽트)를 발생시켜 CPU에 네트워크 데이터가 도착했음을 알린다.
하드웨어 인터럽트란?
사용자가 키보드에서 특정 키를 눌렀을 때, 이를 처리하는 과정은 다음과 같다.
- 키보드는 하드웨어 인터럽트를 발생시켜 CPU에 신호를 보낸다.
- CPU는 현재 수행 중인 작업을 중단하고, 해당 인터럽트를 처리할 적절한 인터럽트 서비스 루틴(ISR)으로 전환한다.
- ISR은 키 입력 값을 저장하거나 입력 버퍼에 적재하며, 필요할 경우 대기 중인 프로그램을 깨워 입력을 처리한다.
하지만 키보드와 달리 네트워크 처리는 상대적으로 복잡하고 시간이 오래 걸리는 작업이다.
만약 모든 네트워크 처리를 하드 인터럽트에서 직접 수행한다면, CPU가 과도하게 점유되어 키보드, 마우스 같은 다른 장치의 입력에 원활하게 응답할 수 없게 된다.
이를 방지하기 위해, CPU는 하드 인터럽트 요청을 받으면 모든 처리를 수행하지 않고 간단한 작업만 수행한 후 제어권을 반환한다.
그리고 시간이 오래 걸리는 네트워크 패킷 처리 작업은 소프트 인터럽트(소프트웨어 인터럽트)로 전환하여 처리한다.
여기서 하드 인터럽트를 처리한 CPU가 동일한 소프트웨어 인터럽트도 처리한다.
소프트 인터럽트는 하드 인터럽트보다 시간적으로 덜 중요하므로, 커널은 소프트 인터럽트들을 대기열에 올려 나중에 처리할 수 있게 하는데, 이 과정에서 커널 스레드 ksoftirqd 가 소프트 인터럽트 요청을 감지하고, 요청 유형에 따라 적절한 처리를 수행한다.
ksoftirqd는 소프트 인터럽트가 너무 많아 인터럽트 모드에서 처리하기 어려울 때, 프로세스 컨텍스트에서 처리하게 하는 커널 스레드이다.
이때, 네트워크 드라이버의 poll 함수가 호출되며, poll()은 RingBuffer에서 데이터 프레임을 가져와 sk_buff에 복사한 후 프로토콜 스택(TCP/IP 계층)으로 전달한다.
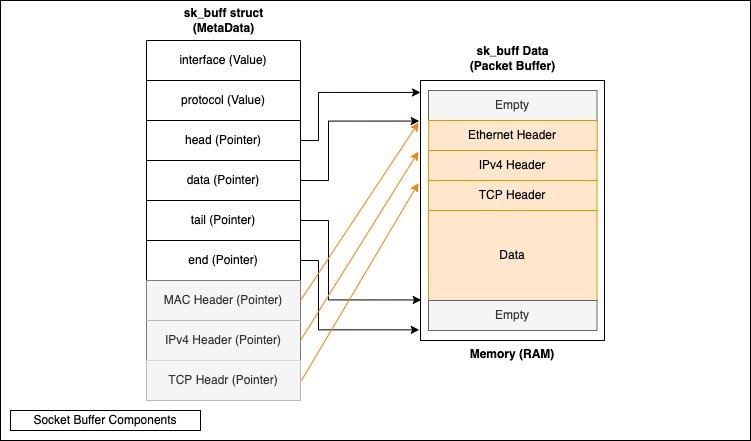
sk_buff
sk_buff 버퍼는 네트워크 프레임을 포함하는 양방향 연결 리스트이다.
리스트의 각 요소는 전송될 네트워크 패킷을 나타내며, 네트워크 계층 간에 데이터를 전달할 때 데이터 구조 내 포인터만을 조작하여 효율적인 전송을 가능하게 한다.
이 방식은 데이터를 복사하지 않고도 TCP/IP계층간의 전송을 가능하게 한다.
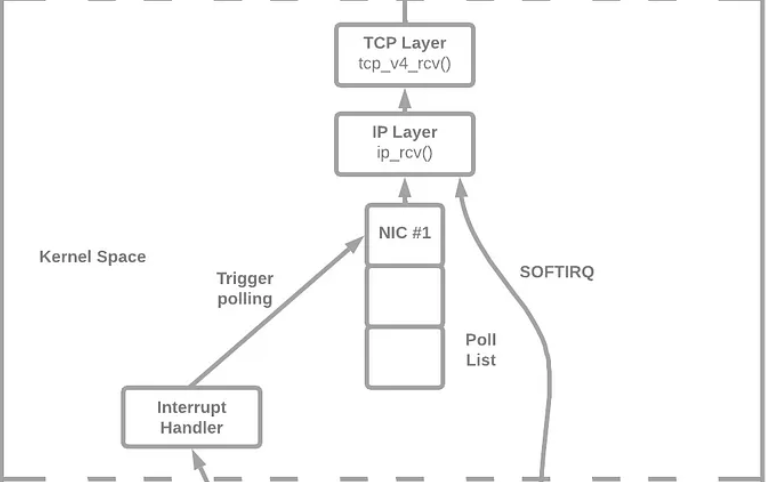
poll 함수는 sk_buffer의 네트워크 데이터 패킷을 커널 프로토콜 스택에 등록된 ip_rcv 함수로 전달한다.
ip_rcv 함수에서는 데이터 패킷의 IP 헤더를 추출하여 데이터 패킷의 다음 홉(hop)을 결정한다.
데이터 패킷이 로컬 머신으로 전송되는 경우, 전송 계층 프로토콜 유형(TCP 또는 UDP)을 추출하고 데이터 패킷의 IP 헤더를 제거한 후, 데이터 패킷을 위의 전송 계층으로 전달하여 처리한다.
TCP 프로토콜은 커널 프로토콜 스택에 등록된 tcp_rcv 함수, UDP 프로토콜은 커널 프로토콜 스택에 등록된 udp_rcv 함수로 처리한다.
tcp_rcv 함수에서는 TCP 헤더를 제거하고, 4-튜플(출발지 IP, 출발지 포트, 목적지 IP, 목적지 포트)을 기반으로 해당 소켓을 찾는다.
해당 소켓을 찾으면 네트워크 데이터 패킷의 전송 데이터를 소켓의 수신 버퍼에 복사합니다. 찾지 못하면 대상에 도달할 수 없다는 ICMP 패킷을 보낸다.
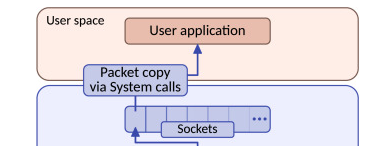
User
프로그램이 시스템 호출 read를 통해 소켓 수신 버퍼의 데이터를 읽을 때, 수신 버퍼에 데이터가 없으면 애플리케이션은 시스템 호출에서 블로킹되어 소켓 수신 버퍼에 데이터가 있을 때까지 기다린다.
데이터가 도착하면 CPU는 커널 공간(소켓 수신 버퍼)의 데이터를 사용자 공간으로 복사하고, 마지막으로 시스템 호출 read()가 리턴되어 애플리케이션이 데이터를 읽게된다.
이 과정에서 많은 성능 오버헤드가 발생한다.
- DMA가 네트워크 데이터 패킷을 메모리에 복사할 때의 오버헤드.
- CPU가 하드 인터럽트에 응답할 때의 오버헤드.
- 커널 스레드 ksoftirqd가 소프트 인터럽트에 응답할 때의 오버헤드.
- 네트워크 데이터가 커널 공간에서 CPU를 통해 사용자 공간으로 복사될 때의 오버헤드.
- 애플리케이션이 시스템 호출을 통해 사용자 모드에서 커널 모드로 전환될 때의 오버헤드와 시스템 호출이 반환될 때 커널 모드에서 사용자 모드로 전환될 때의 오버헤드.
참고문헌 :
https://serhack.me/articles/techniques-setting-up-pheripherals-dma-pio/
https://developer.aliyun.com/article/1391040
https://blog.naver.com/fafali/140125667821
https://parker1609.github.io/post/network-basic-tcp-and-ip/
https://www.baeldung.com/linux/signals-vs-interrupts#2-inner-workings-of-hardware-interrupts
'백엔드' 카테고리의 다른 글
| OAuth2.0에 대해 간단하게 알아보자 (0) | 2024.05.27 |
|---|
